模型表示及代价函数
本文共 568 字,大约阅读时间需要 1 分钟。
监督式学习的模型表示
训练集的描述:
如:
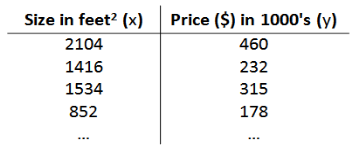
m 代表训练集中实例的数量
x 代表特征/输入变量
y 输出变量
(x,y) 代表训练集中的实例
(xi,yi) 代表第 i 个观察实例
h 代表学习算法的解决方案或函数也称为假设(hypothesis)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jm7BIPTq-1605151502349)(https://s1.ax1x.com/2020/11/09/BHuxJJ.png)]
上面为一个监督式学习的工作方式,将我们的训练集数据喂食给这个算法,然后可以给我们返回一个函数h代表学习算法给我们的解决方案,我们可以通过这个函数来根据输入判断输出,就比如根据房子的尺寸估计出房子的价格,h函数相当于一个从x到y的映射,h函数的表达方式有很多种比如最简单的单变量线性表示,抑或多变量一次线性表示来拟合数据,或者多次幂函数来拟合更为复杂的数据。
非监督式学习
非监督式学习与监督式学习的区别主要在于,非监督式学习的训练集数据并不会包含这个数据实例的正确答案,而是依靠非监督式学习算法自己去寻找这些数据的各自特点,一个主要的应用就是应用在聚类算法上面如:
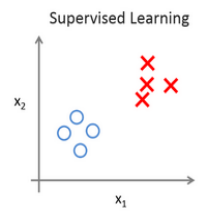
那么聚类算法的作用就是寻找这两波数据的特点,并映射到h函数中,以求能够将两类数据区分出来。
代价函数的介绍
转载地址:http://oicki.baihongyu.com/
你可能感兴趣的文章
GCC编译关键字“__attribute_…
查看>>
GCC编译关键字“__attribute_…
查看>>
Linux对I/O端口资源的管理( …
查看>>
Linux对I/O端口资源的管理( …
查看>>
[转载]Linux内核中的platfor…
查看>>
[转载]Linux内核中的platfor…
查看>>
IO端口和IO内存 (转载)
查看>>
IO端口和IO内存 (转载)
查看>>
Linux内核驱动模块
查看>>
Linux内核驱动模块
查看>>
linux中同步例子(完成量completion…
查看>>
linux中同步例子(完成量completion…
查看>>
Linux驱动中completion接口…
查看>>
Linux驱动中completion接口…
查看>>
顺序和屏障 收藏
查看>>
顺序和屏障 收藏
查看>>
LINUX内核调试相关--oops信息的…
查看>>
LINUX内核调试相关--oops信息的…
查看>>
linux内核的oops信息
查看>>
linux内核的oops信息
查看>>